



Do you ever find yourself with a mountain of PDFs to read and wish you had a magical helper to make it all easier? Well, I have fantastic news! There is this amazing technology called ChatGPT and LangChain that can help you conquer your PDF quests like a hero! In this blog post, we'll explore how these work together to make your PDF experience a breeze. Let's get started!
Pre-requisites:
Install the required python libraries
pip install langchain pypdf chromadb openai tiktoken
Let us import the required libraries
import os
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
Setting the OpenAI API Key
To use the OpenAI GPT-based model for generating embeddings, you need to provide your OpenAI API key:
os.environ['OPENAI_API_KEY'] = 'ENTER YOUR API KEY'
Replace 'ENTER YOUR API KEY' with your actual OpenAI API key.
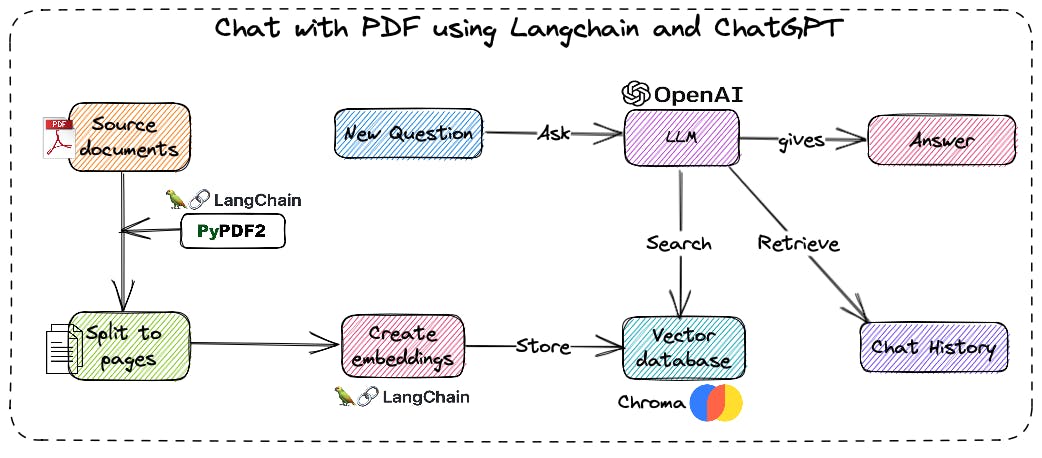
Loading the PDF Document
I will be using the Indian Constitution PDF as my source document. To load the PDF, we use the PyPDFLoader class:
pdf_path = "./indian_constitution.pdf"
loader = PyPDFLoader(pdf_path)
pages = loader.load_and_split()
PyPDFLoader loads the PDF file and splits it into pages.
Generating Embeddings
Now, we create an instance of OpenAIEmbeddings, which is responsible for generating embeddings for text:
embeddings = OpenAIEmbeddings()
Creating a Vector Store
To create a vector store, we use the Chroma class, which takes the documents (pages in our case), the embeddings instance, and a directory to store the vector data:
vectordb = Chroma.from_documents(pages, embedding=embeddings,
persist_directory=".")
Next, we persist the vector store:
vectordb.persist()
Initializing Conversation Buffer Memory
We create an instance of ConversationBufferMemory to store the conversation history:
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
Creating the bot
Finally, we create the bot using the ConversationalRetrievalChain class:
pdf_qa = ConversationalRetrievalChain.from_llm(OpenAI(temperature=0.9) , vectordb.as_retriever(), memory=memory)
Querying the bot
To query the bot, we can use the following code:
query = "What is Right to equality?"
result = pdf_qa({"Question": query})
print("Answer:")
result["answer"]
Answer:
Article 14 in the Constitution of India guarantees all citizens of India the right to equality before the law or the equal protection of the laws within the territory of India.
Here, we ask the question "What is Right to equality?" and the system retrieves the relevant answer from the Indian Constitution.
The complete code is as follows
import os
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
os.environ['OPENAI_API_KEY'] = 'ENTER YOUR API KEY'
pdf_path = "./indian_constitution.pdf"
loader = PyPDFLoader(pdf_path)
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(pages, embedding=embeddings,
persist_directory=".")
vectordb.persist()
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
pdf_qa = ConversationalRetrievalChain.from_llm(OpenAI(temperature=0.9) ,
vectordb.as_retriever(), memory=memory)
query = "What is Right to equality?"
result = pdf_qa({"Question": query})
print("Answer:")
result["answer"]
Conclusion
In this tutorial, I have explained how to chat with your PDF document using the langchain library and ChatGPT API. The bot can answer questions about the content of the PDF by analyzing the text and retrieving relevant information. By following the steps provided, you can create a similar chatbot for any other PDF documents.